Maximum-entropy Markov model
In machine learning, a maximum-entropy Markov model (MEMM), or conditional Markov model (CMM), is a graphical model for sequence labeling that combines features of hidden Markov models (HMMs) and maximum entropy (MaxEnt) models. An MEMM is a discriminative model that extends a standard maximum entropy classifier by assuming that the unknown values to be learned are connected in a Markov chain rather than being conditionally independent of each other. MEMMs find applications in natural language processing, specifically in part-of-speech tagging[1] and information extraction.[2]
Contents |
Model
Suppose we have a sequence of observations  that we seek to tag with the labels
that we seek to tag with the labels  that maximize the conditional probability
that maximize the conditional probability 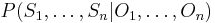 . In a MEMM, this probability is factored into Markov transition probabilities, where the probability of transitioning to a particular label depends only on the observation at that position and the previous position's label:
. In a MEMM, this probability is factored into Markov transition probabilities, where the probability of transitioning to a particular label depends only on the observation at that position and the previous position's label:
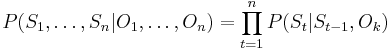
Each of these transition probabilities come from the same general distribution 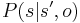 . For each possible label value of the previous label
. For each possible label value of the previous label 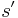 , the probability of a certain label
, the probability of a certain label 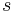 is modeled in the same way as a maximum entropy classifier [3]:
is modeled in the same way as a maximum entropy classifier [3]:
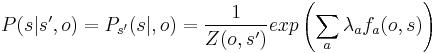
Here, the 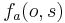 are real-valued or categorical feature-functions, and
are real-valued or categorical feature-functions, and 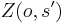 is a normalization term ensuring that the distribution sums to one. This form for the distribution corresponds to the maximum entropy probability distribution satisfying the constrain that the empirical expectation for the feature is equal to the expectation given the model:
is a normalization term ensuring that the distribution sums to one. This form for the distribution corresponds to the maximum entropy probability distribution satisfying the constrain that the empirical expectation for the feature is equal to the expectation given the model:
![\forall a, \; \mathbb{E}_e\left[f_a(o,s)\right] = \mathbb{E}_p\left[f_a(o,s)\right]](/2012-wikipedia_en_all_nopic_01_2012/I/de269fa00f6844be6da72c33241a635d.png)
The parameters 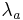 can be estimated using Generalized Iterative Scaling[4]. Furthermore, A variant of the Baum–Welch algorithm, which is used for training HMMs, can be used to estimate parameters when training data has incomplete or missing labels [2].
can be estimated using Generalized Iterative Scaling[4]. Furthermore, A variant of the Baum–Welch algorithm, which is used for training HMMs, can be used to estimate parameters when training data has incomplete or missing labels [2].
The optimal state sequence can be found using a very similar Viterbi algorithm to the one used for HMMs. The dynamic program uses the forward probability:
Strengths and Weaknesses
An advantage of MEMMs rather than HMMs for sequence tagging is that they offer increased freedom in choosing features to represent observations. In sequence tagging situations, it is useful to use domain knowledge to design special-purpose features. In the original paper introducing MEMMs, the authors write that "when trying to extract previously unseen company names from a newswire article, the identity of a word alone is not very predictive; however, knowing that the word is capitalized, that is a noun, that it is used in an appositive, and that it appears near the top of the article would all be quite predictive (in conjunction with the context provided by the state-transition structure). "[2] Useful sequence tagging features, such as these, are often non-independent. Maximum entropy models do not assume independence between features, but generative observation models used in HMMs do [2]. Therefore, MEMMs allow the user to specify lots of correlated, but informative features.
Another advantage of MEMMs versus HMMs and Conditional random fields (CRFs) is that training can be considerably more efficient. In HMMs and CRFs, one needs to use some version of the Forward–backward algorithm as an inner loop in training. However, in MEMMs, estimating the parameters of the maximum-entropy distributions used for the transition probabilities can be done for each transition distribution in isolation.
A drawback of MEMMs is that they potentially suffer from the "label bias problem," where states with low-entropy transition distributions "effectively ignore their observations." Conditional random fields were designed to overcome this weakness.[5] Another source of label bias is that training is always done with respect to known previous tags, so the model struggles at test time when there is uncertainty in the previous tag.
Software
References
- ^ Toutanova, Kristina; Manning, Christopher D. (2000). "Enriching the Knowledge Sources Used in a Maximum Entropy Part-of-Speech Tagger". Proc. J. SIGDAT Conf. on Empirical Methods in NLP and Very Large Corpora (EMNLP/VLC-2000). pp. 63–70.
- ^ a b c d McCallum, Andrew; Freitag, Dayne; Pereira, Fernando (2000). "Maximum Entropy Markov Models for Information Extraction and Segmentation". Proc. ICML 2000. pp. 591–598.
- ^ Berger, A.L. and Pietra, V.J.D. and Pietra, S.A.D. (1996). "A maximum entropy approach to natural language processing". 22. MIT Press. 39--71.
- ^ Darroch, J.N. and Ratcliff, D. (1972). "Generalized iterative scaling for log-linear models". 43. Institute of Mathematical Statistics. 1470--1480.
- ^ Lafferty, John; McCallum, Andrew; Pereira, Fernando (2001). "Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data". Proc. ICML 2001.